

Overview:
In our previous article (part 1), we demonstrated how to stream order data from the Order Management System (OMS) directly into Salesforce Data Cloud, eliminating the need for external systems or connectors. In this blog, we’ll explore how Bulk Ingestion works in Data Cloud to efficiently bring large datasets into the platform in a single batch. You start by preparing your data in files (such as CSV), uploading them, and then creating an ingestion job that maps the data to the appropriate Data Cloud objects. Once uploaded, Data Cloud validates and processes the data, making it ready for segmentation, insights generation, and activation.
Use Case: Bulk Ingestion
We’re working with an Order Management System (OMS) that stores all customer purchase history. While streaming ingestion helps us capture new orders in real time, the business also needs to load historical and large-volume order data into Salesforce Data Cloud for analytics and reporting. For example, the OMS generates daily CSV exports of all completed orders, which include details such as Order ID, Customer ID, Order Date, Amount, and Status. Since Data Cloud doesn’t have a native connector for the OMS, the Bulk Ingestion API provides a direct way to upload these CSV files into Data Cloud.
This allows us to refresh the complete order history regularly, ensuring teams can run advanced analysis, segment customers based on lifetime value, and track sales trends—all without relying on intermediate systems.
Solution Approach:
To solve the challenge of bringing large volumes of order history from our Order Management System (OMS) into Salesforce Data Cloud, we leveraged the Bulk Ingestion API. The data is exported from the OMS as a CSV file, which we then upload into Data Cloud in batches.
To set up the integration, we first defined a YAML configuration file that describes the order schema, including fields like orderId, customerId, orderDate, amount, and status. This YAML ensures that the uploaded CSV rows are correctly mapped to the OMS_Orders Data Lake Object in Data Cloud.
With this setup in place, we can bulk-ingest historical or periodic order data efficiently.
We followed the steps below to achieve this:
Step 1: Set up the Ingestion API connector
- Go to Data Cloud Setup → Ingestion API → New [create a new connector by giving it a name i.e.OMS_Bulk_Ingestion]
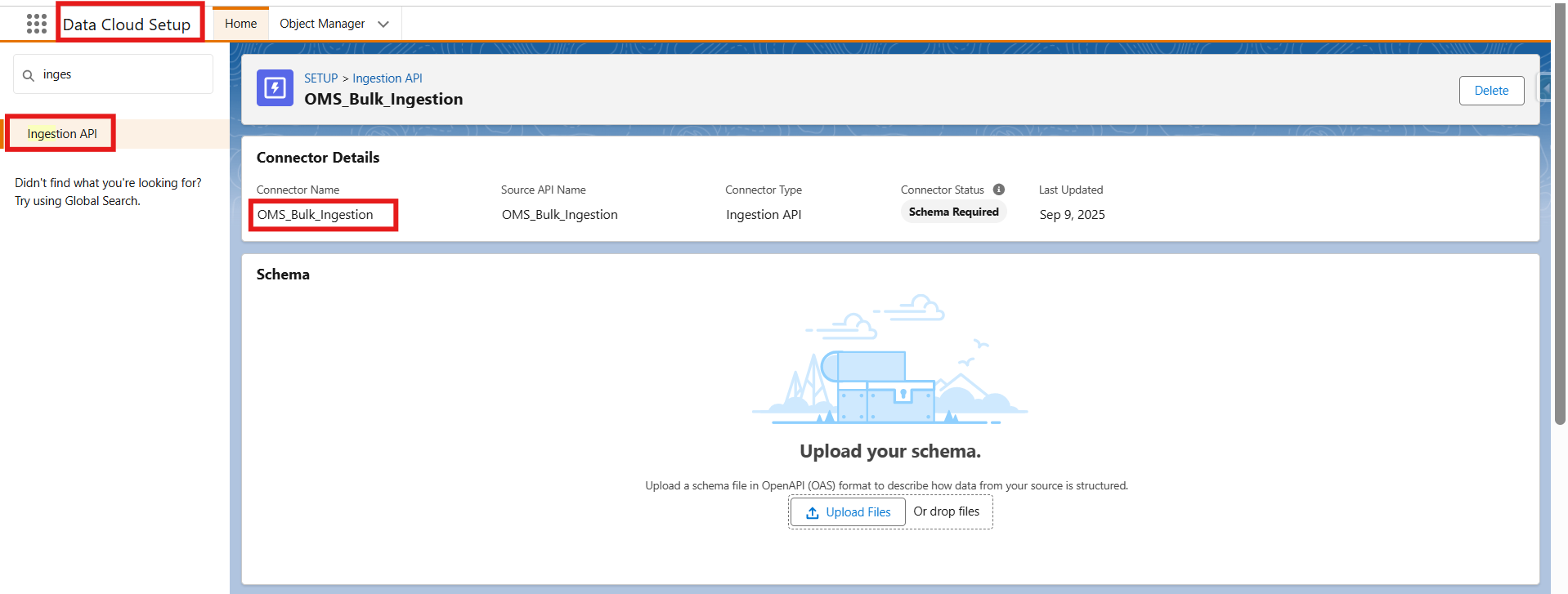
- Click Save
- Once the connector is created, the next step is to upload a schema file in OpenAPI (YAML) format. This file defines the structure of the data coming from the OMS, including key fields like orderId, customerId, orderDate, and amount. By uploading this YAML file, you’re essentially mapping these OMS fields to the corresponding Data Lake Object fields in Data Cloud—ensuring the data flows in correctly and is ready for processing. Open the created connector and upload a schema file in OpenAPI (YAML) format.
Note: Below is the sample code to create a file with yaml extension.openapi: 3.0.3 info: title: 'OMS Orders Bulk Ingestion' version: 1.0.0 components: schemas: OMS_Orders: type: object properties: orderId: type: string customerId: type: string orderDate: type: string format: date-time amount: type: number format: float status: type: string - Once uploaded, verify that objects and fields appear with the correct datatypes.
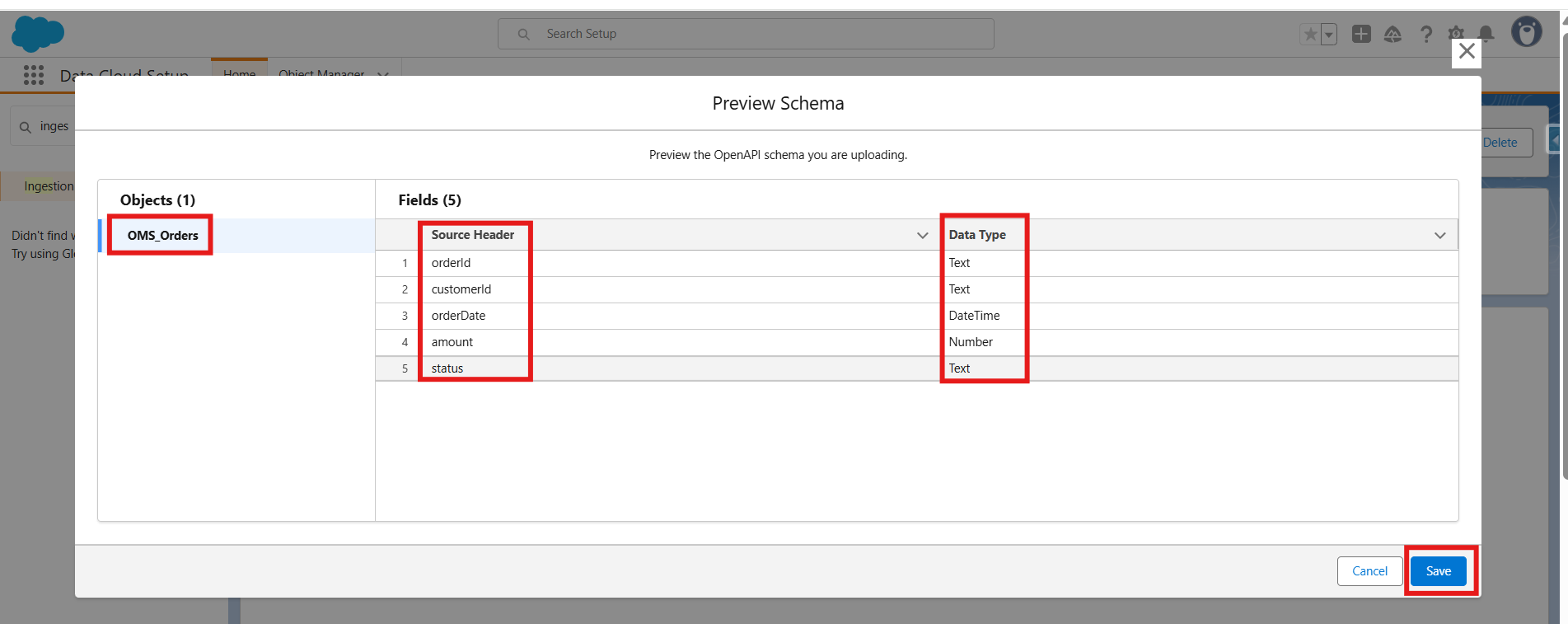
- Save the file, it will be uploaded successfully.
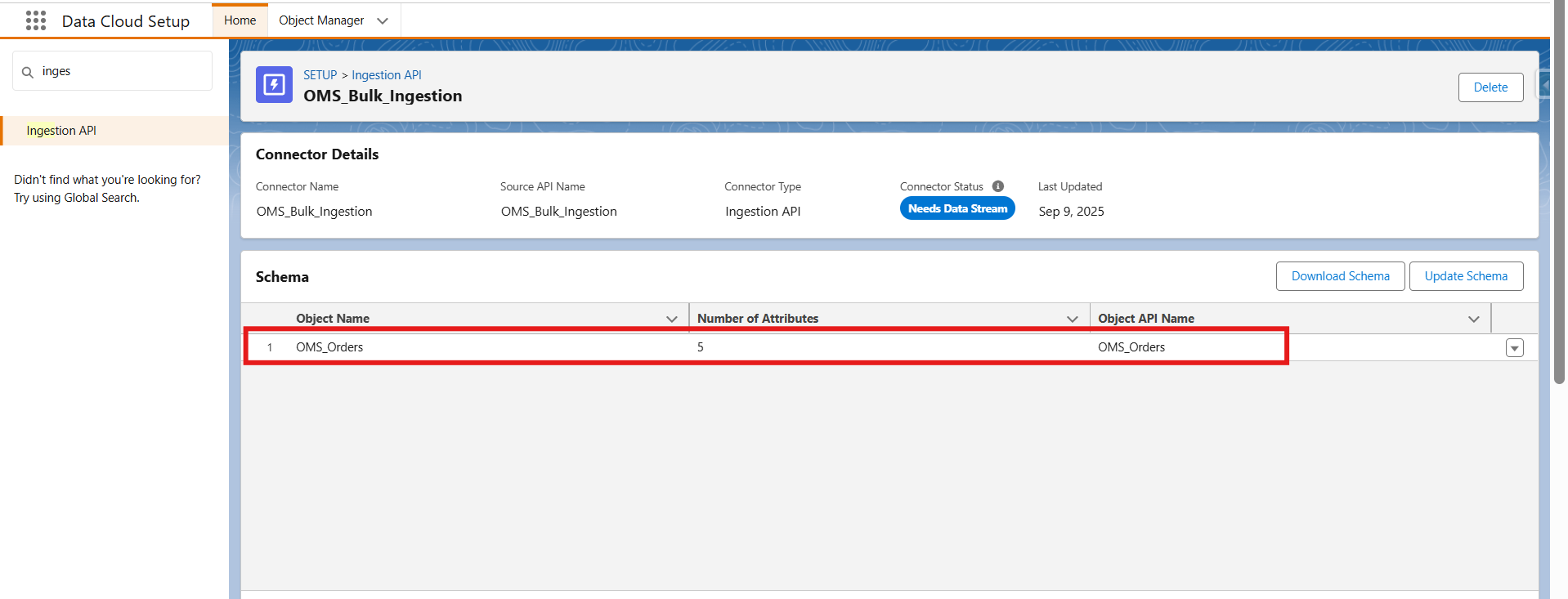
Step 2: Create and deploy a Data lake object and data stream
- Go to App Launcher -> Data Cloud -> Data Lake Objects -> New
- Select New to create a new Data Lake Object
- Provide the Object name that you have written in the schema. In this case object name is OMS_Orders, and click on the Add Field button to add the field which you have described in the YAML file.
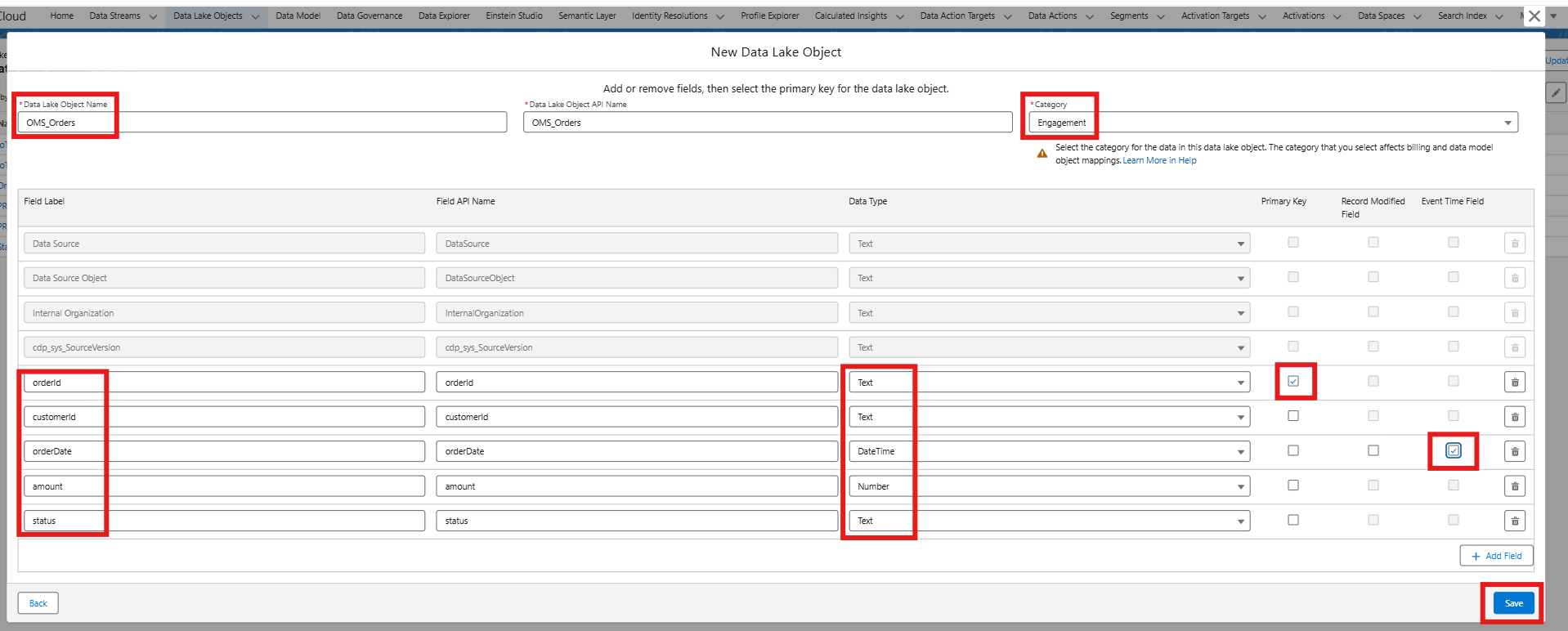
- Save it.
- Go to App Launcher -> Data Cloud -> Data Streams -> New
- Select Ingestion API as the source.
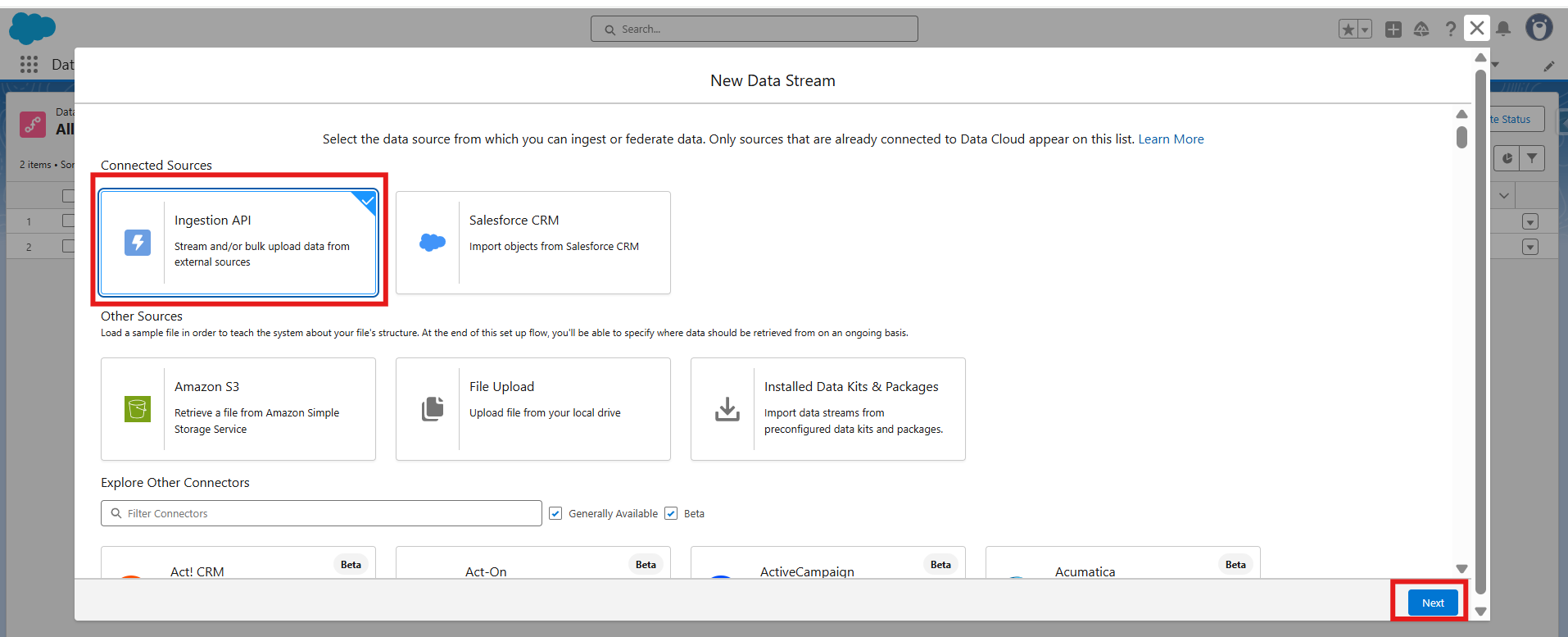
- Choose the connector created in Step 1 (OMS_Bulk_Ingestion).
- Select the ingestion object (e.g., OMS_Orders).
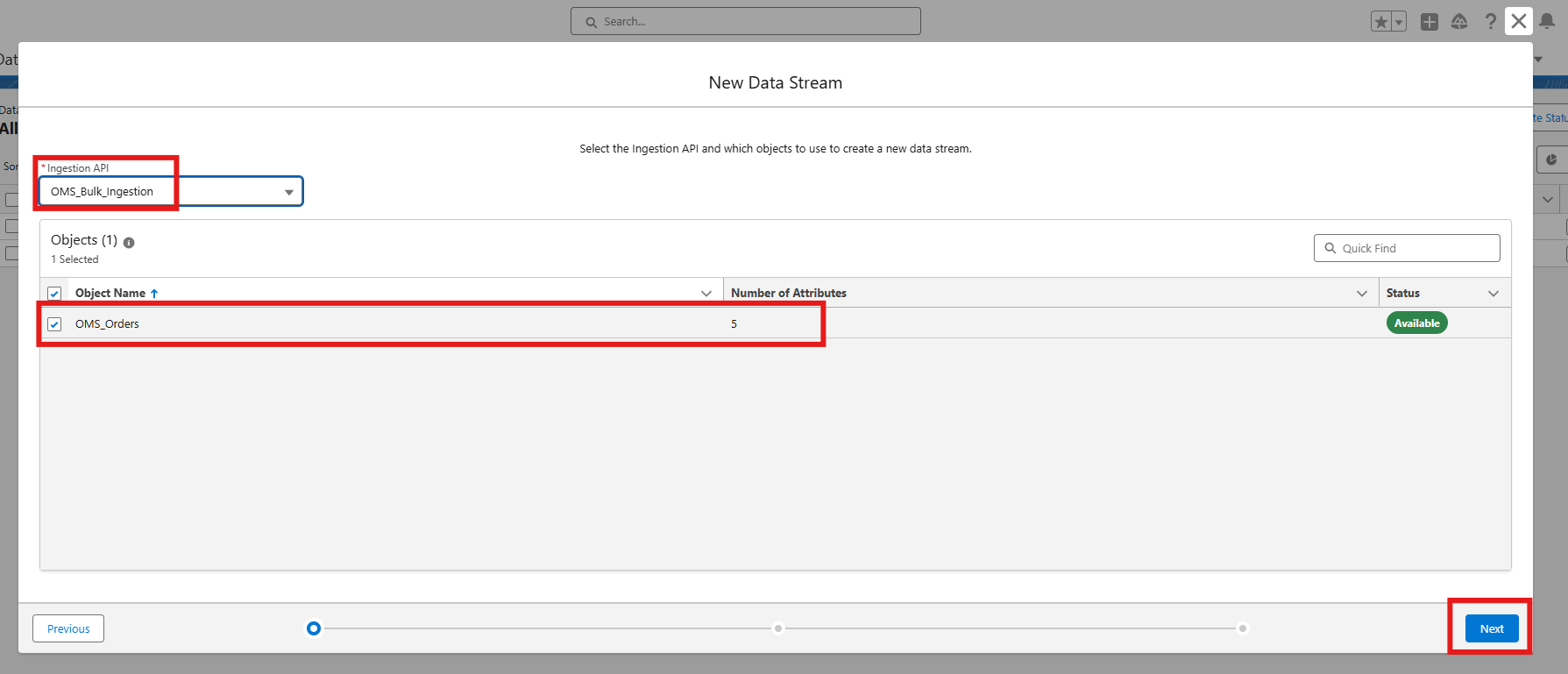
- Configure the object:
Category → Engagement
Primary Key → orderId
Event Time Field → orderDate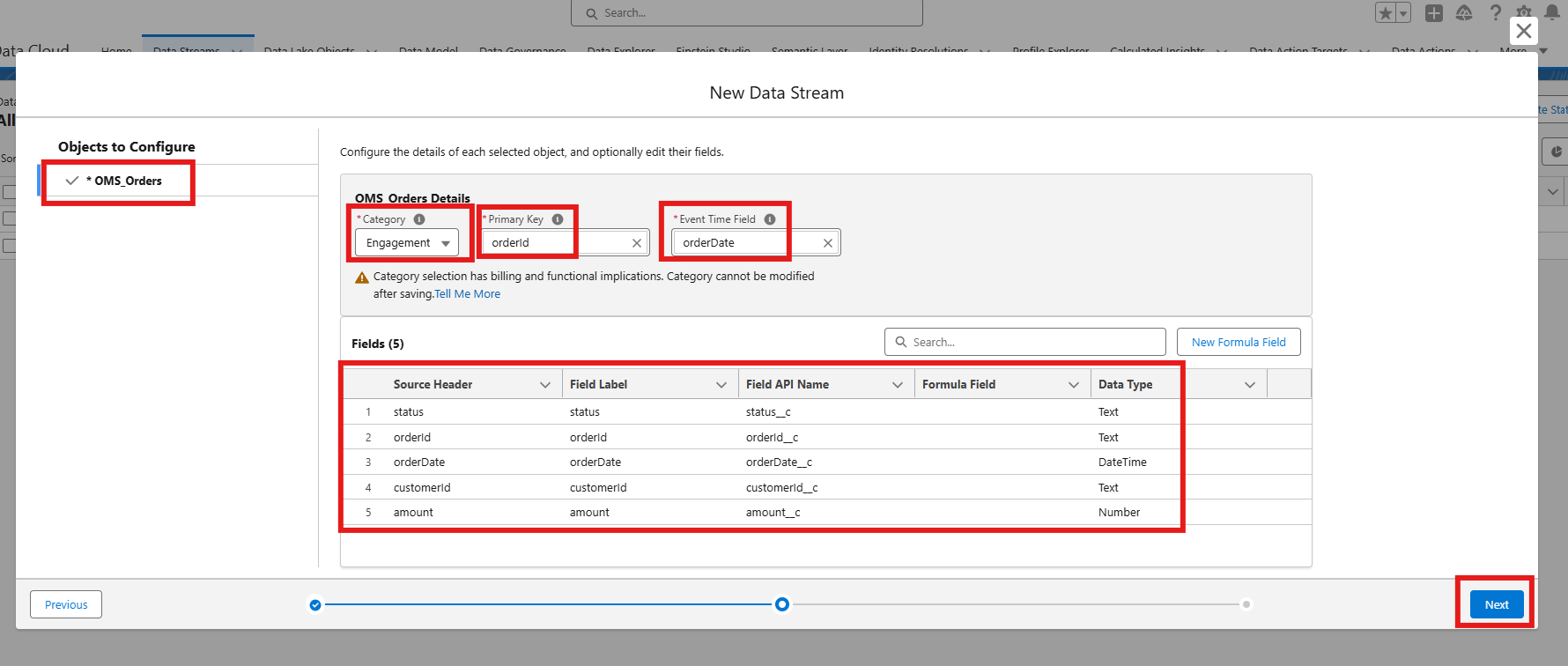
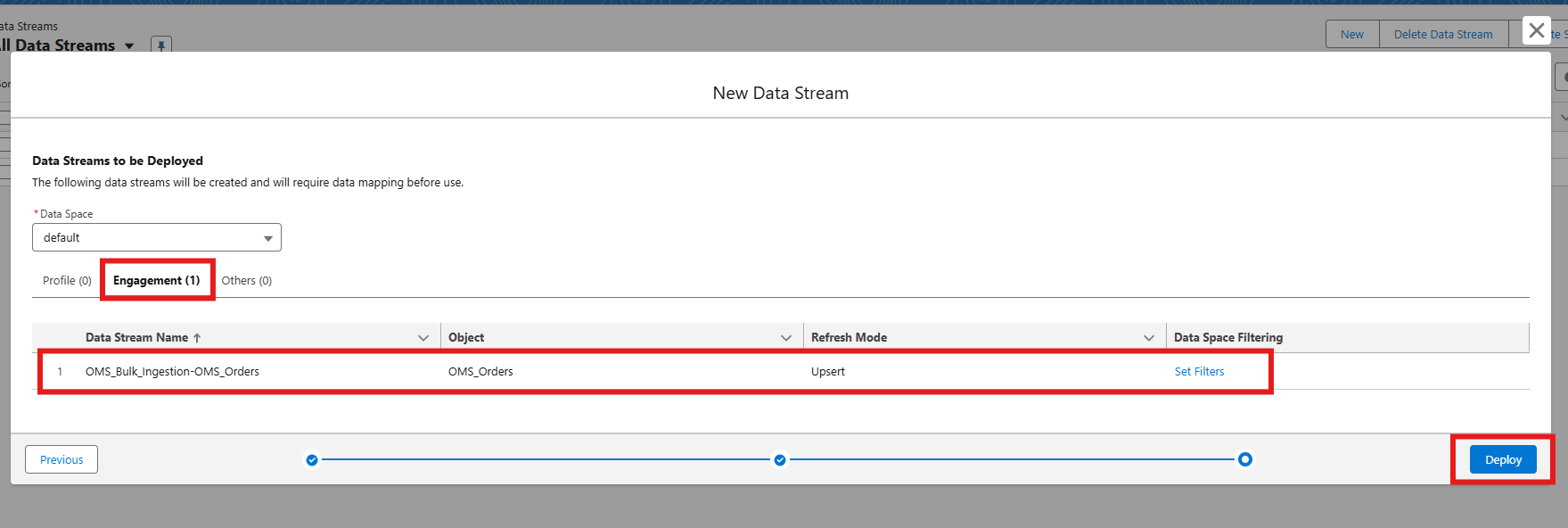
- Map fields if needed, then click Next and deploy the data stream.
Step 3: Create a Connected App (steps shared in part 1)
- Use Postman (or any REST client) with the connected app credentials to authenticate.
- Generate a token on clicking Get a New Access Token
Step 4: Push Data Using API (via Postman to process sample data)
- Create a new Job in Postman. We need to define the sourceName and object.
Sample Create Job Payload:POST URL : https://{{_dcTenantUrl}}/api/v1/ingest/jobs { "object": "runner_profiles", "sourceName": "Event_API", "operation": "upsert" }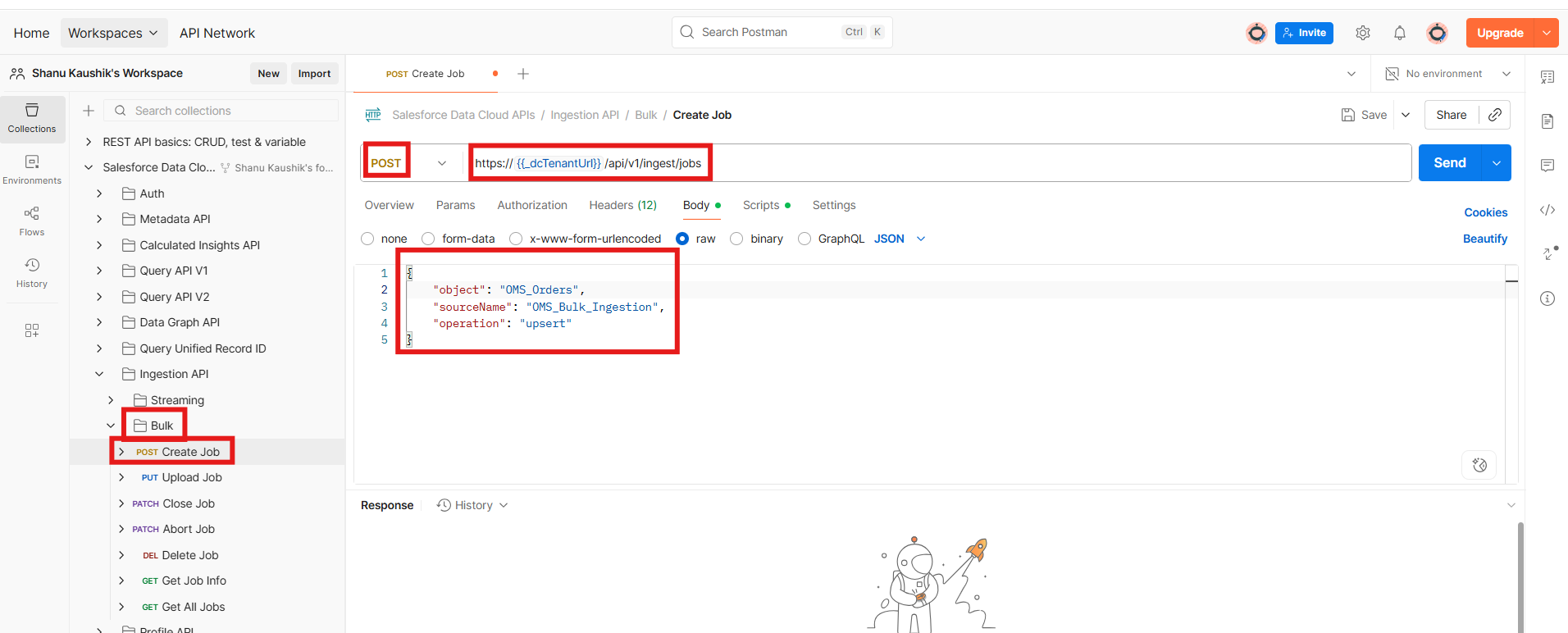
- Click on the Send button and get the JobId in response.
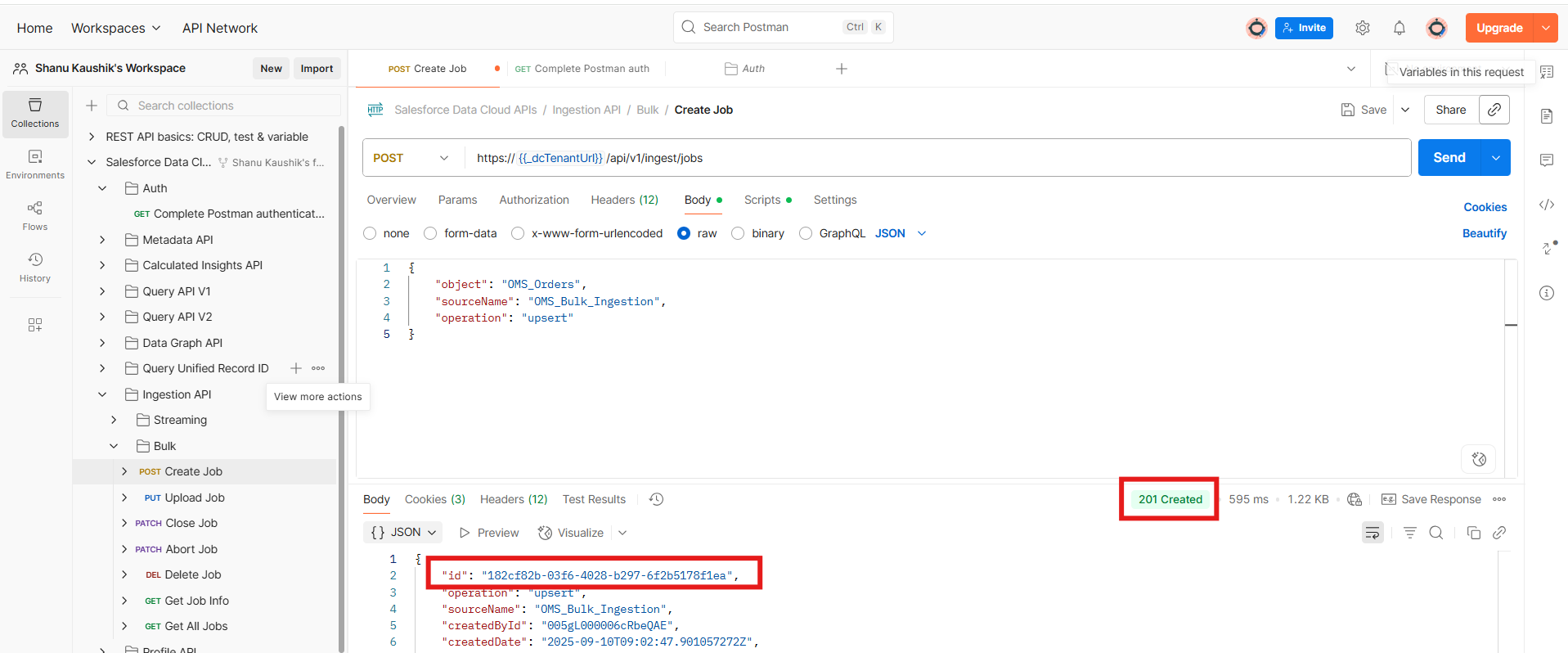
- Using JobId, PUT the CSV data to upload for ingestion.
PUT URL : https://{{_dcTenantUrl}}/api/v1/ingest/jobs/:jobId/batches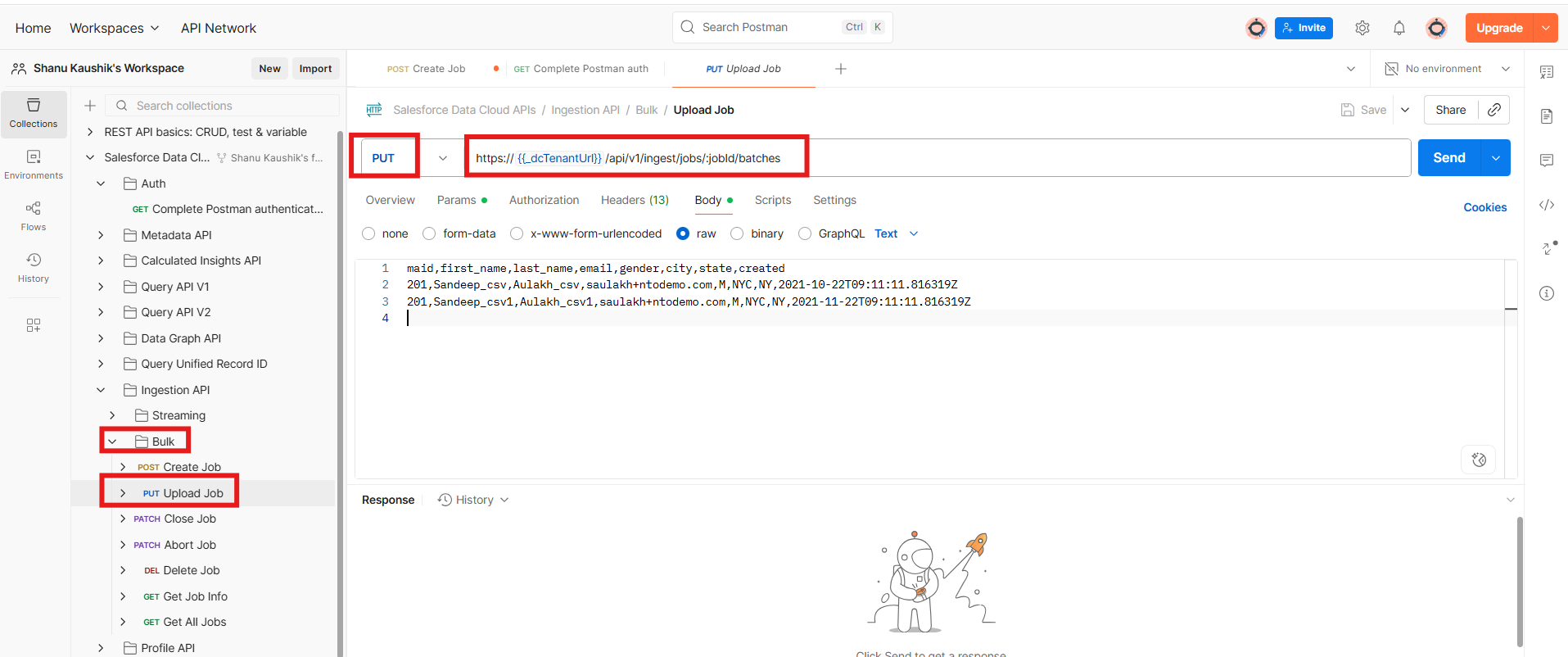
- Provide your csv data here and click send.
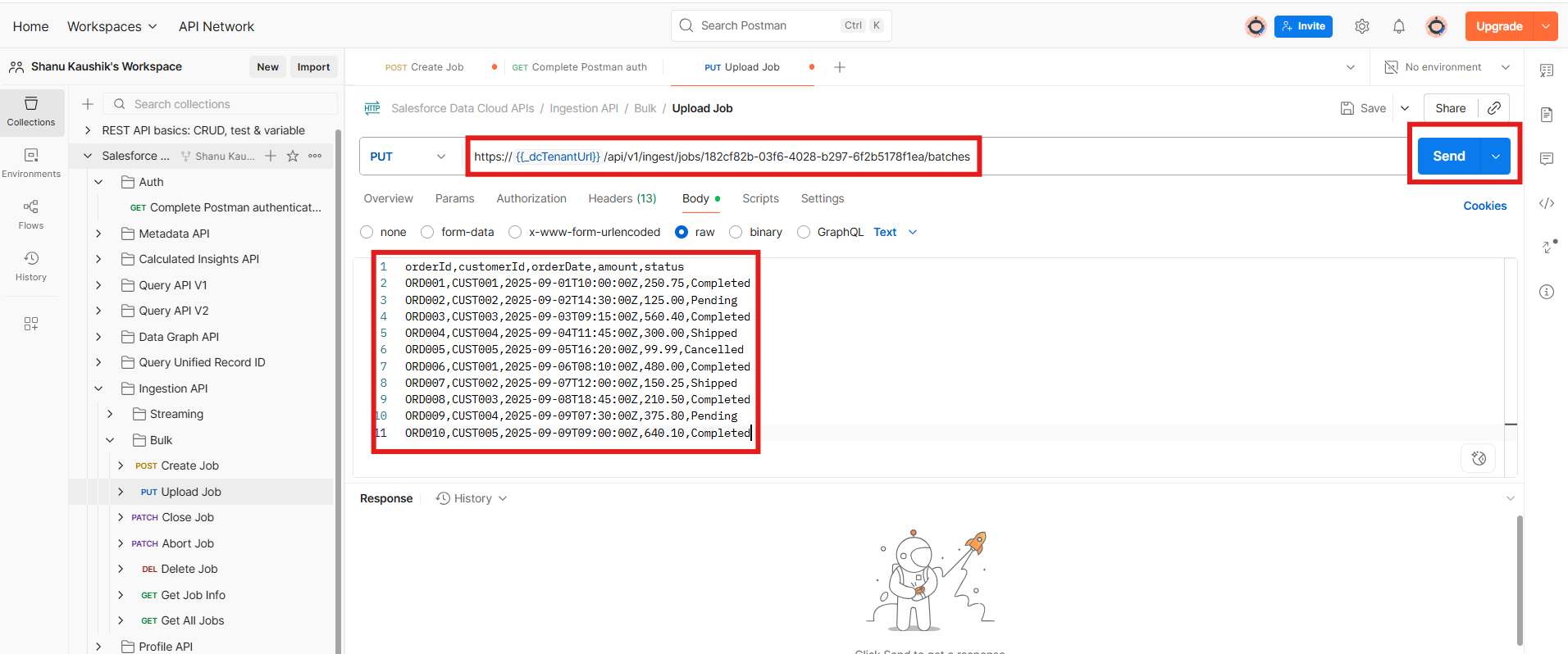
- When you get the response as ‘true’ then your data is successfully uploaded to the data cloud.
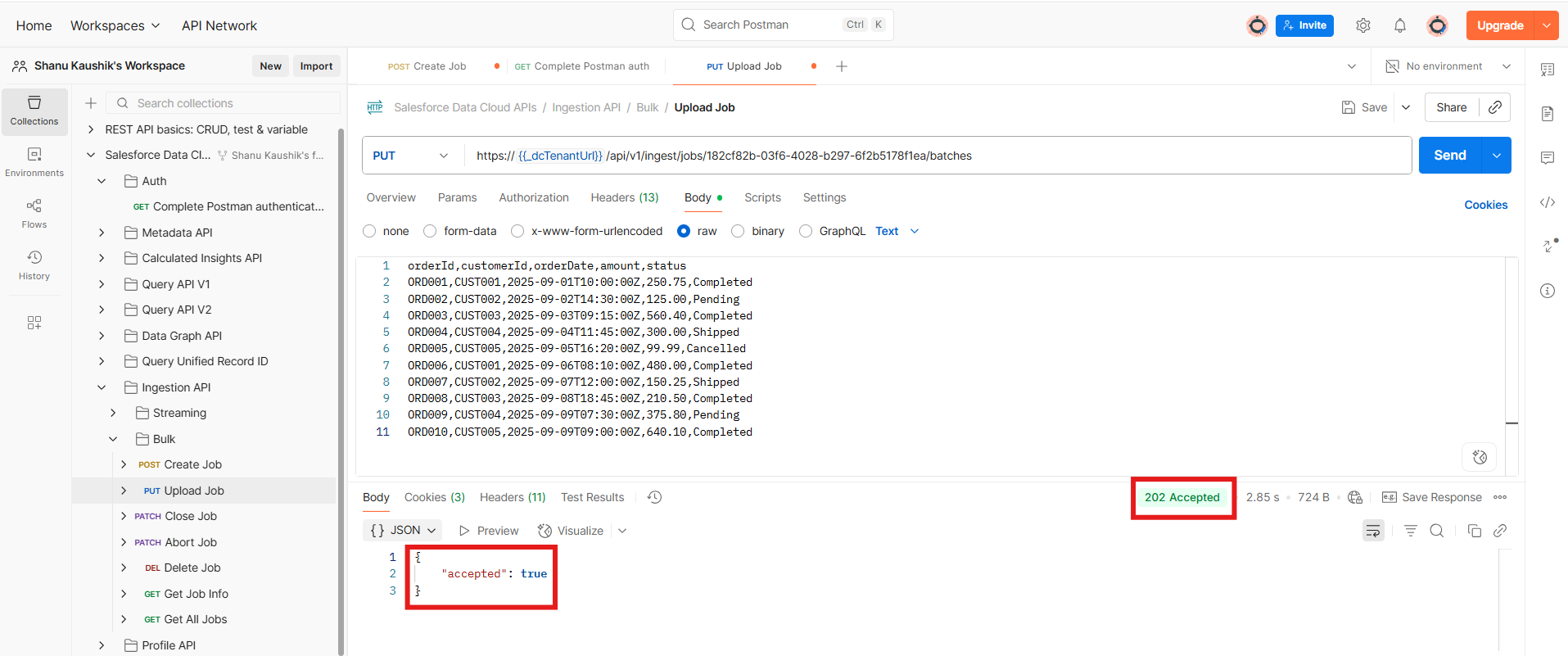
- Closing the Job: Once the data upload is complete, the next step is to close the ingestion job. To do this, simply provide the jobId and click Send. You’ll receive a response indicating that the upload state is complete.
If you need to upload a new batch of data, repeat the job creation steps to initiate a fresh ingestion process
Sample Close Job Payload :PATCH URL : https://{{_dcTenantUrl}}/api/v1/ingest/jobs/:jobId { "state" : "UploadComplete" }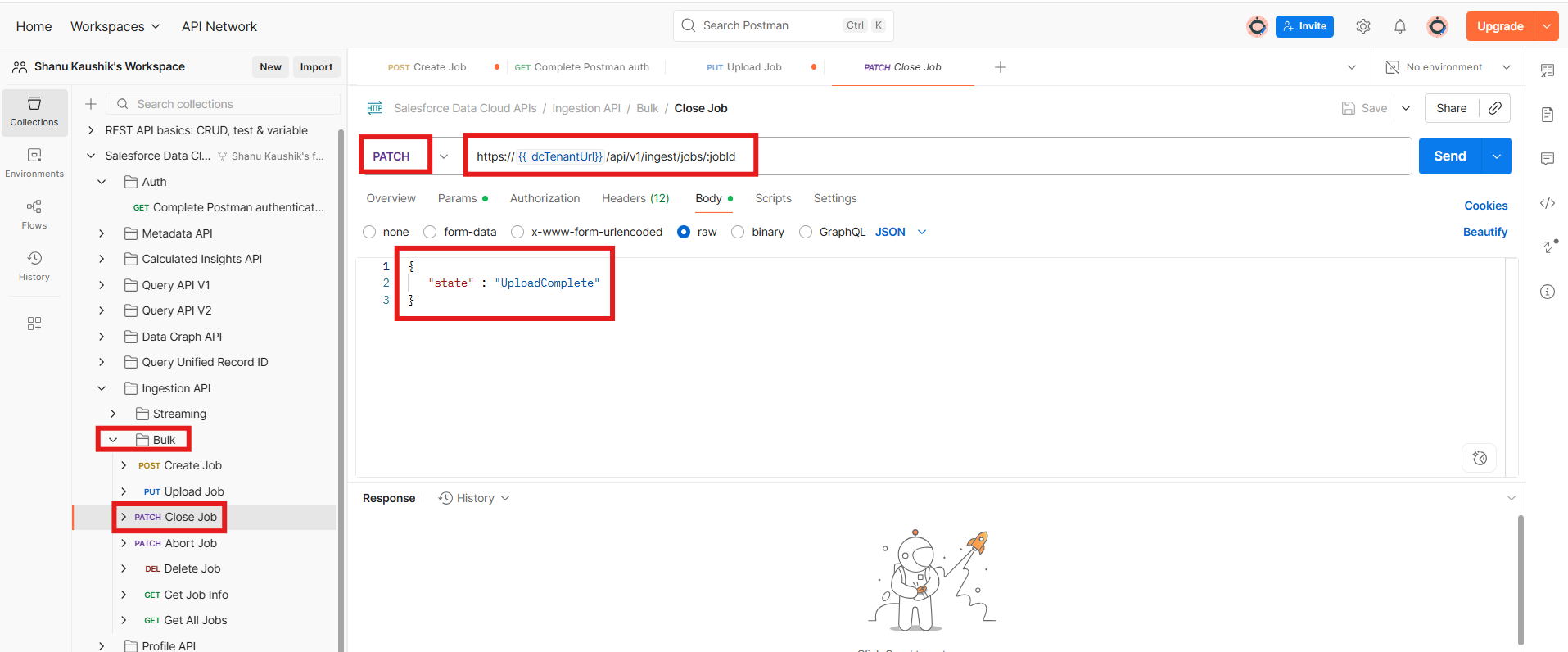
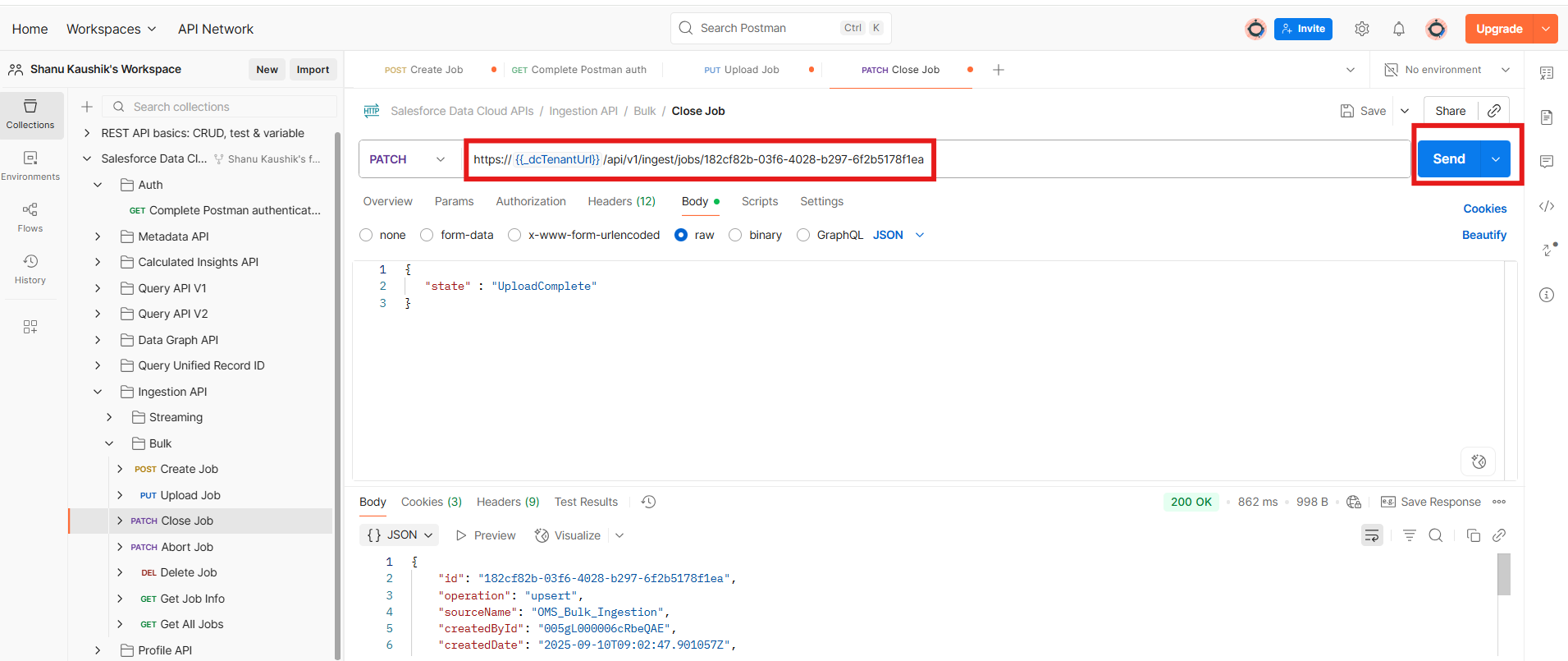
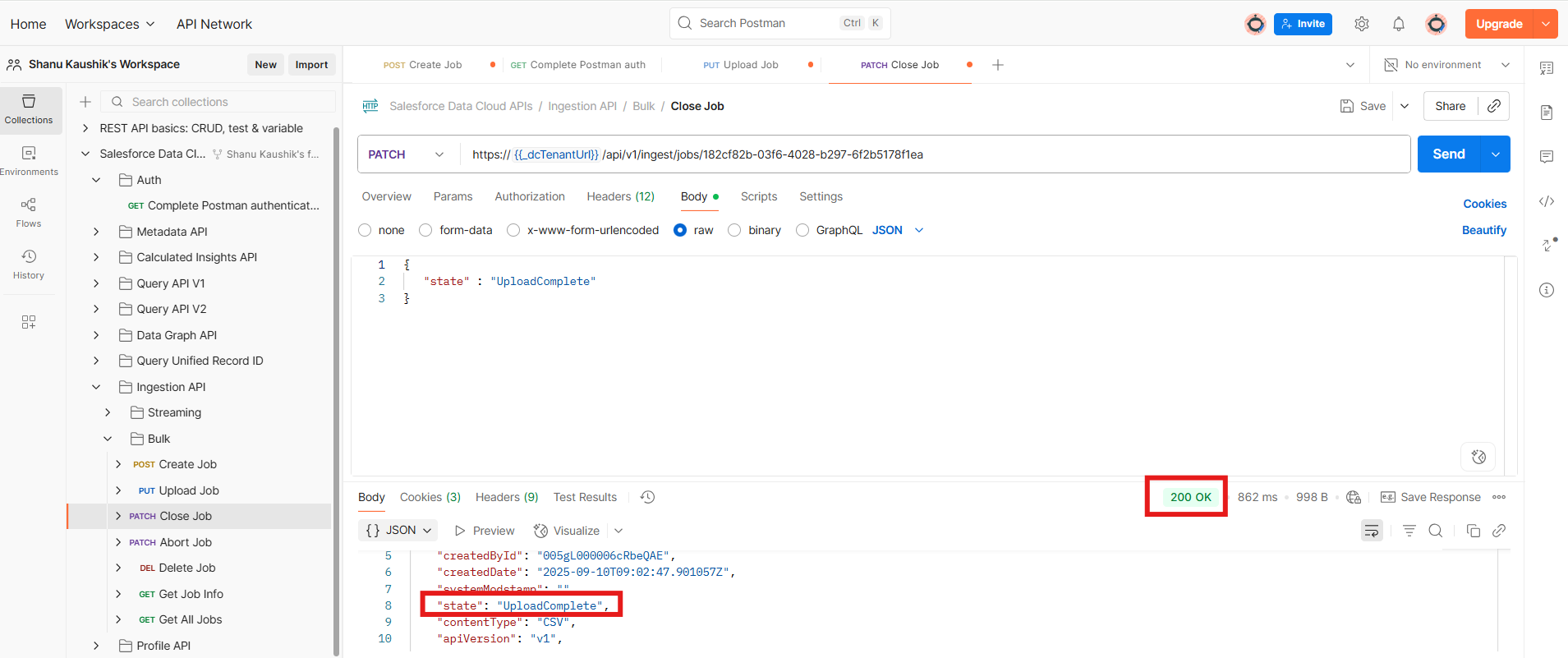
- Verify records in Data Cloud by checking the deployed data stream.
Go to App Launcher -> Data Cloud -> Data Explorer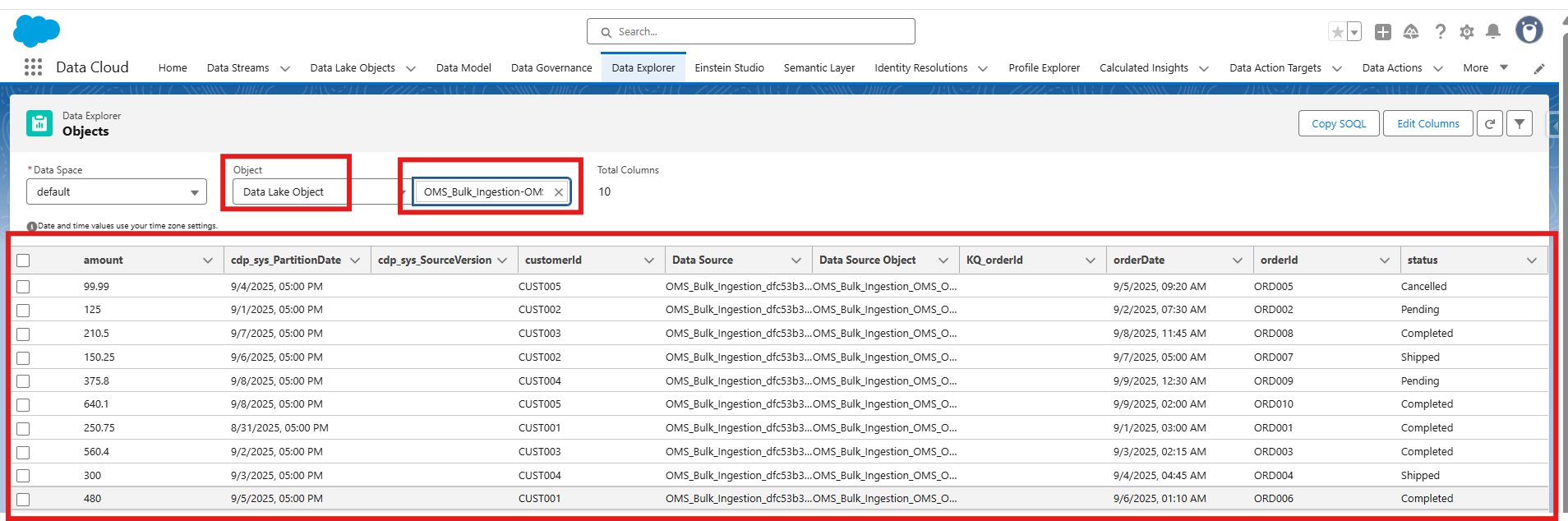
- Select the Data Lake Object and your source name. The data streams are mapped with the data that we posted from the Postman.
Conclusion:
By using the Ingestion API for historical data, we were able to upload large volumes of order data from our OMS into Salesforce Data Cloud in a single, efficient batch process. Through steps such as defining the schema, creating a data lake object, preparing CSV files, and managing ingestion jobs with Postman(for testing purposes), we ensured that entire batches of customer purchase records flow seamlessly into Data Cloud. This approach not only streamlines the integration but also provides a reliable way to keep Data Cloud updated with historical and daily order data—empowering the business with richer insights and more comprehensive analytics.
Want to explore streaming data ingestion?
Click here to check out the previous part of this post, where we dive into how to send real-time streaming of data into Data Cloud using the Streaming Ingestion method.



